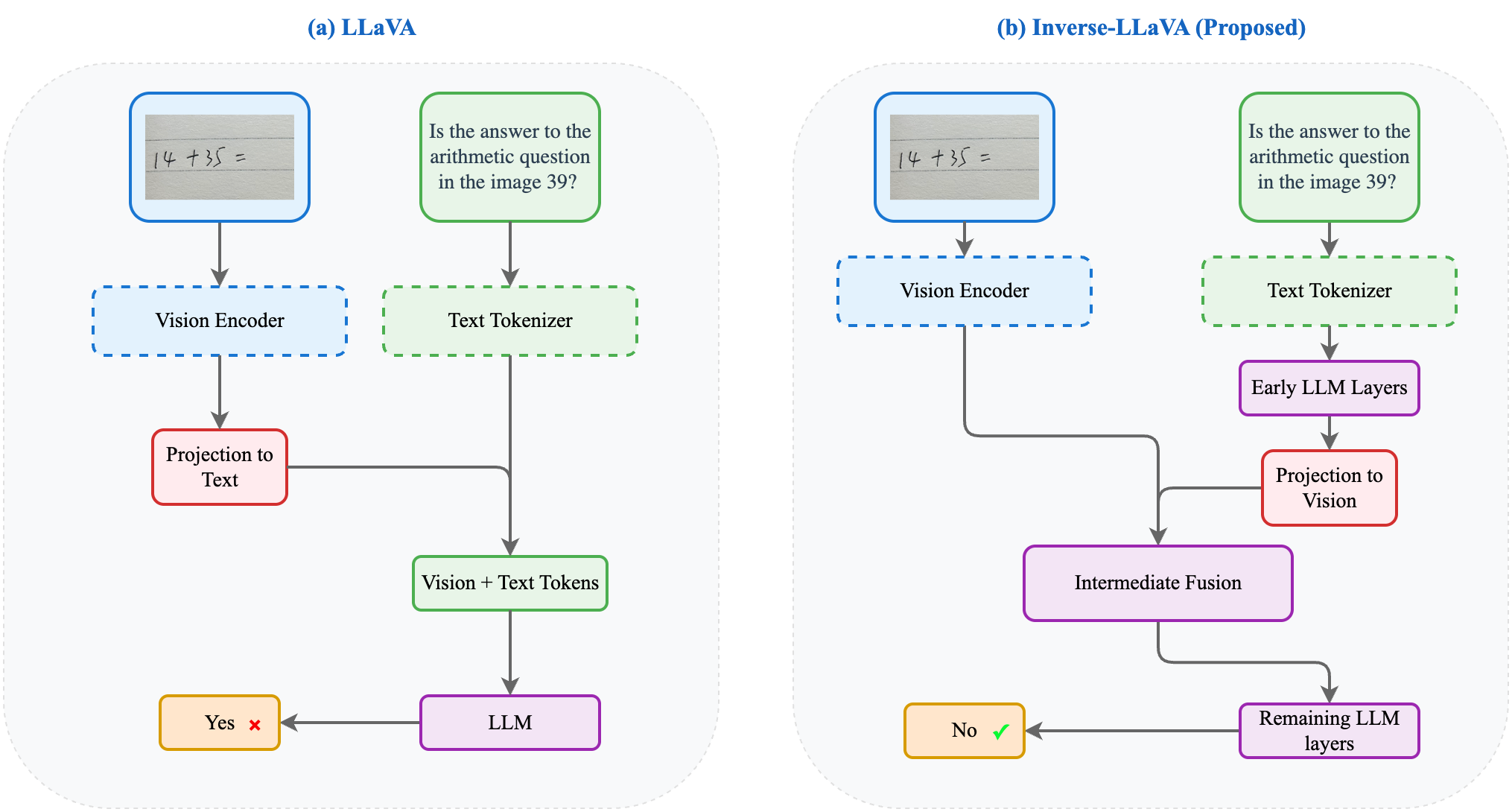
Traditional multimodal learning approaches require expensive alignment pre-training to bridge vision and language modalities, typically projecting visual features into discrete text token spaces. We challenge both fundamental assumptions underlying this paradigm by proposing Inverse-LLaVA, a novel approach that eliminates alignment pre-training entirely while inverting the conventional mapping direction. Rather than projecting visual features to text space, our method maps text embeddings into continuous visual representation space and performs fusion within transformer intermediate layers. Through selective additive components in attention mechanisms, we enable dynamic integration of visual and textual representations without requiring massive image-text alignment datasets. Comprehensive experiments across nine multimodal benchmarks demonstrate nuanced performance trade-offs: Inverse-LLaVA achieves notable improvements on reasoning-intensive and cognitive tasks (MM-VET: +0.2%, VizWiz: +1.8%, ScienceQA: +0.2%, cognitive reasoning: +27.2%), while showing expected decreases in perception tasks requiring memorized visual-text associations (celebrity recognition: -49.5%, OCR: -21.3%). These results provide the first empirical evidence that alignment pre-training is not necessary for effective multimodal learning, particularly for complex reasoning tasks. Our work establishes the feasibility of a new paradigm that reduces computational requirements by 45%, challenges conventional wisdom about modality fusion, and opens new research directions for efficient multimodal architectures that preserve modality-specific characteristics.
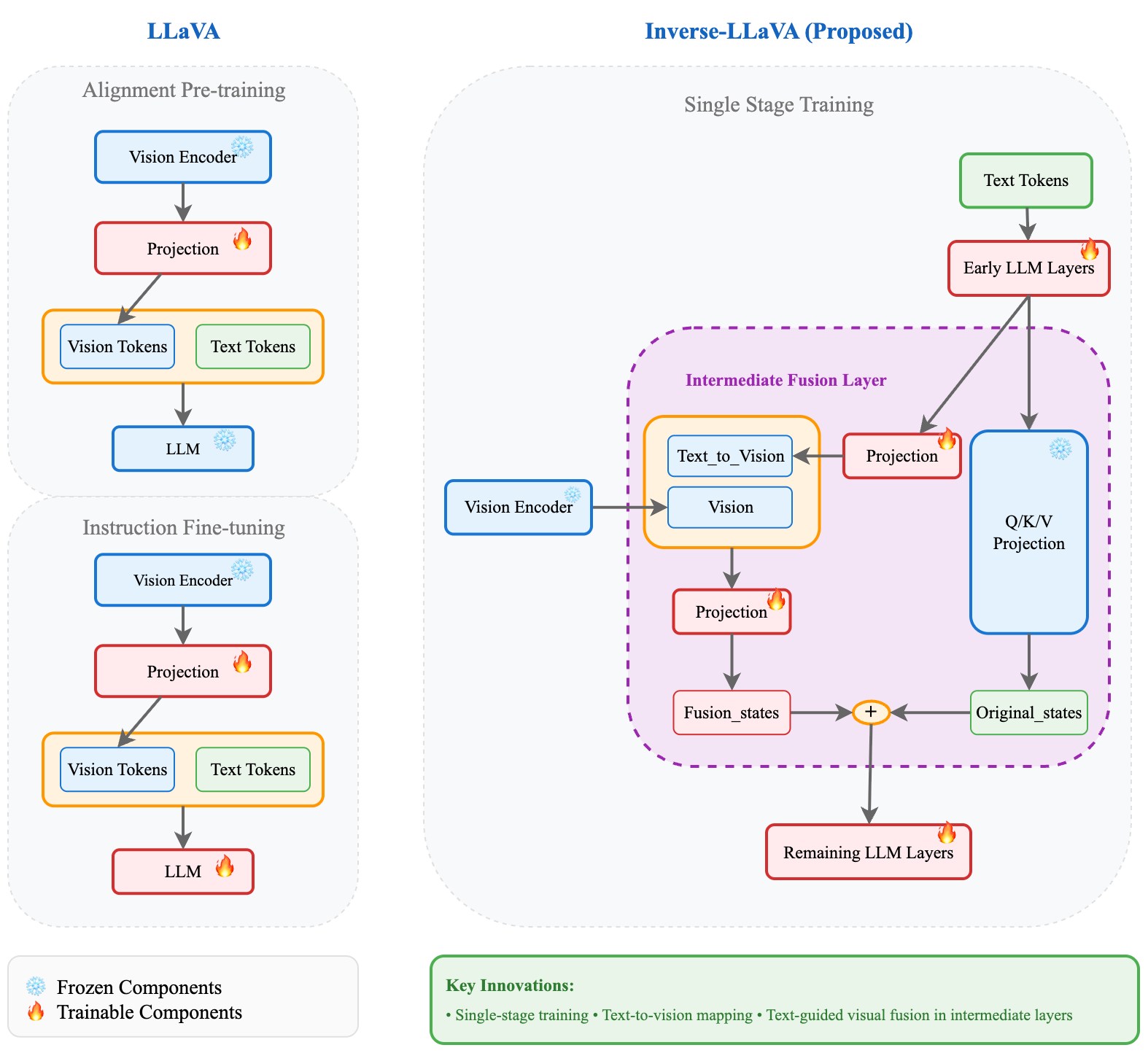
Architecture comparison between LLaVA and Inverse-LLaVA. LLaVA employs a two-stage training approach with alignment pretraining followed by instruction fine-tuning, where vision and text tokens are concatenated before being fed to the LLM. In contrast, Inverse-LLaVA uses single-stage training with text-guided visual fusion in intermediate layers, where vision information is integrated through learnable text-to-vision projections and combined with original hidden states via residual connections.
Table 1 demonstrates that our inverse mapping approach achieves competitive performance across nine vision-language benchmarks while fundamentally rethinking how modalities interact. Unlike conventional methods that compress visual features to match text distributions, we project text embeddings into the richer visual space, preserving spatial relationships and fine-grained visual details. The results reveal selective advantages: Inverse-LLaVA outperforms LLaVA-1.5 on MM-VET (31.2 vs 31.1), VizWiz (50.95 vs 50.0), and notably on ScienceQA-IMG (67.84 vs 66.80). However, we observe consistent degradation on tasks requiring precise visual-text alignment, including TextVQA (52.02 vs 58.2) and GQA (58.46 vs 62.0). This performance pattern suggests our approach excels at reasoning tasks while struggling with direct visual-linguistic correspondence.
| Model | MM-VET | VizWiz | SQA-IMG | MMB | MMB-CN | MME-p | VQA-V2 | VQA-T | GQA |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA-1.5 | 31.1 | 50.0 | 66.80 | 64.3 | 58.3 | 1510.7 | 78.5 | 58.2 | 62.0 |
| InstructBLIP | 26.2 | 34.5 | 60.5 | 36.0 | 23.7 | - | - | 50.1 | 49.2 |
| InternVL-Chat | - | 52.5 | - | - | - | 1521.1 | 79.3 | 57.0 | 62.9 |
| EVE-7B | 25.6 | 41.8 | 63.0 | 49.5 | - | 1217.3 | 75.4 | 51.9 | 60.8 |
| Inverse-LLaVA | 31.2 | 50.95 | 67.84 | 54.55 | 41.84 | 1293.15 | 74.76 | 52.02 | 58.46 |
| Inverse-LLaVA-HD | - | - | - | - | - | 1335.67 | - | - | 59.33 |
| Model | Alignment #Samples | Finetune #Samples |
|---|---|---|
| LLaVA-1.5 | 558K | 665K |
| InstructBLIP | 129M | 1.2M |
| InternVL-Chat | 4.98B | 665K |
| EVE-7B | 33M | 665K |
| Inverse-LLaVA | 0 | 665K |
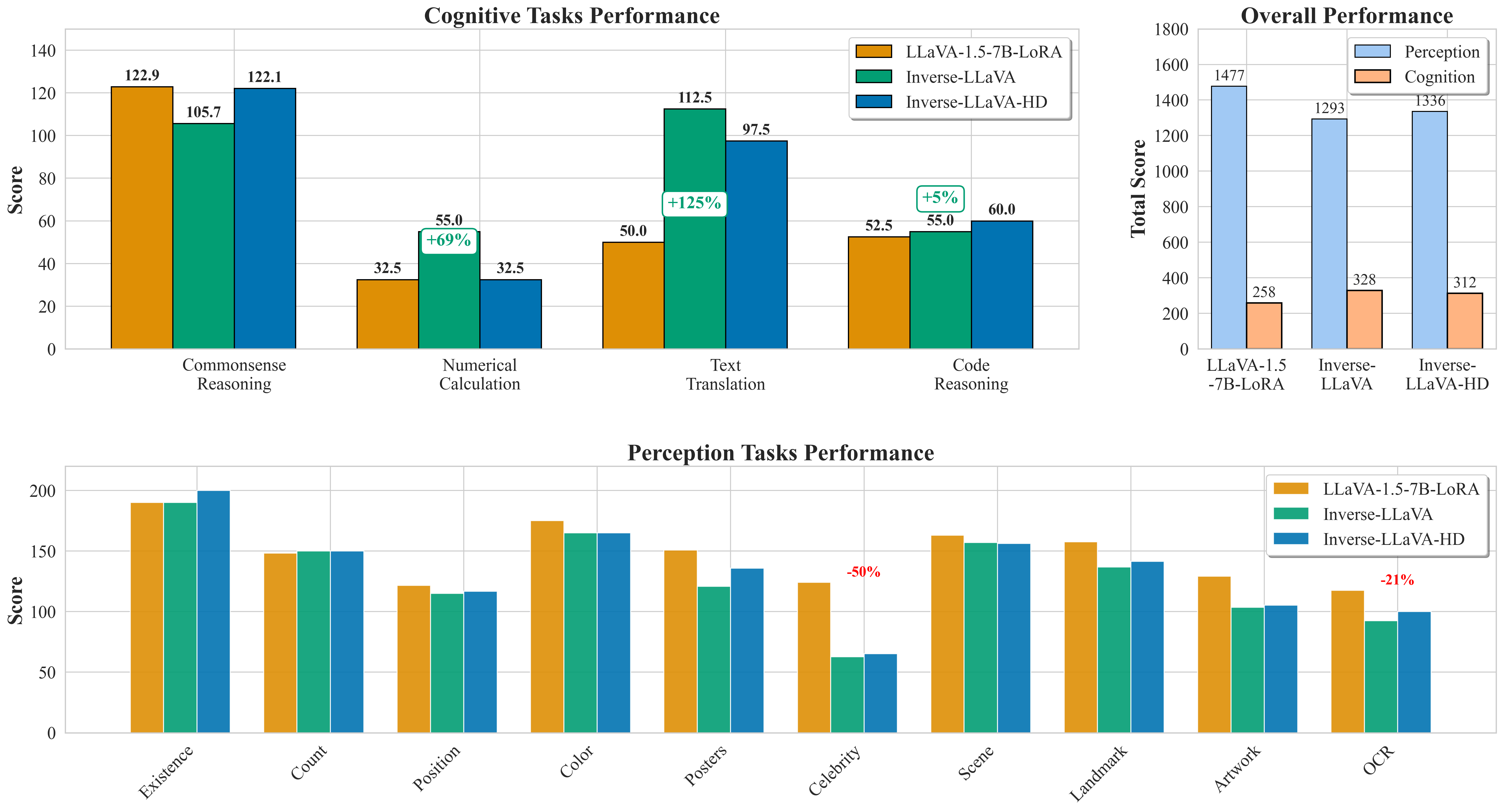
MME Benchmark Analysis comparing LLaVA-1.5-7B-LoRA, Inverse-LLaVA, and Inverse-LLaVA-HD across cognitive and perception tasks in the MME benchmark. Left (top): Cognitive tasks performance showing Inverse-LLaVA achieving superior performance in numerical calculation (+69%) and text translation (+125%) compared to the baseline LLaVA-1.5-7B-LoRA model. Right (top): Overall performance comparison. Bottom: Perception tasks evaluation shows that Inverse-LLaVA variants excel in Existence and Count tasks, with Inverse-LLaVA-HD achieving perfect performance on Existence tasks. However, significant performance drops in Celebrity recognition (-50%) and OCR tasks (-21%) primarily account for the overall perception score gap. The results indicate that inverse training maintains strong cognitive capabilities while showing task-specific effects on perception.
@article{zhan2025inverse,
title={Inverse-LLaVA: Eliminating Alignment Pre-training Through Text-to-Vision Mapping},
author={Zhan, Xuhui and Derr, Tyler},
journal={arXiv preprint arXiv:2508.12466},
year={2025}
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.